
はじめに
開発が終わってからリリースするまで、どんなフローがあるでしょうか?
アプリ開発というくらいなので、開発がメインと感じるかもしれませんが、実は開発が終わってからリリースまでにも、たくさんの工程があります。
今回はその流れを、前後編の2本の記事に分けてご紹介していきます。
前編にあたる本記事では、私が実際のプロジェクトで経験して学んだ「開発完了後からリリース前までの流れ」のうち、前半で行われる機能テストとモニタリング設計について整理します。
リリース前の確認というと、まず「作った機能が正しく動くか」に目が向きます。
しかし実際には、それだけではなく、リリース後に問題が起きたときに気づける状態を作っておくことも重要です。
まずは機能テストの種類と使い分けを整理し、その後に、非機能試験や本番運用につながるモニタリング設計について見ていきます。
また後編では、機能テストとモニタリング設計の次の工程である、非機能試験についてを整理します。
プロジェクトで経験する前の私と同じように、「テストの種類が多くて混乱している」「結合テストとE2Eテストの違いが分からない」「モニタリングはいつ設計するものなの?」という方の参考になれば嬉しいです。
この記事は次の流れで進みます。
- 機能をテストする … つくったものが正しく動くか(テストの種類と使い分け)
- モニタリングを設計する … 監視を「試験の前」に整える
それでは、順番に見ていきます。
第1章 機能をテストする — テストの種類と使い分け
開発が「完了した」と言えるのは、書いたコードが意図どおりに動くと確認できたときです。
ただ、ひとことで「確認」と言っても、実はいくつもの層があります。
関数ひとつの正しさを見るテストと、システム全体が利用者の目的を果たすかを見るテストでは、目的も・速さも・壊れやすさもまったく異なります。
テストの種類を理解することで、どの層で何を担保するのか判断しやすくなるので、まずはテストピラミッドから確認していきます。
テストピラミッド
テストの種類は、よく「ピラミッド」で表されます。下にいくほど数が多く・速く・安定し、上にいくほど数が少なく・遅く・壊れやすいという関係が表現されています。
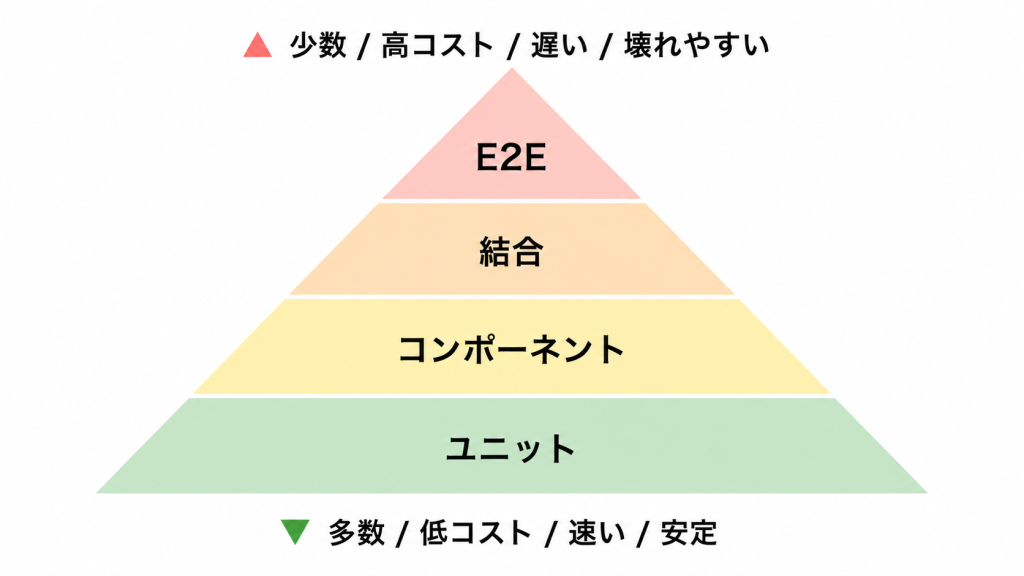
下を厚くする理由としては、上層のテストは多くの部品を一度に通すため、失敗したときに原因の切り分けが難しく、ちょっとした変更でもすぐ壊れてしまうからです。
速くて安定した下層で大半の不具合を捕まえて、上層は「全体が繋がって動くか」の確認に絞る。これがピラミッドになる理由です。
それぞれのテストについて
ユニットテスト(単体)
関数やクラスなど、最小単位のロジックを検証します。
外部依存はモック化し、純粋にロジックの正しさだけを高速で確かめます。
コンポーネントテスト
対象のサービスを1つだけ起動し、他のサービスやDBなどの外部依存をモック化して、そのサービスのAPIを単体で検証します。
マイクロサービスアーキテクチャでは、他サーバーは外部サービスにあたるため、対象のAPIサーバーのみを起動し、他サーバーはモック化します。
「このサービス単体は、要件どおりに振る舞うか?」を、周囲の都合に左右されずに確認することができます。
結合テスト(インテグレーション)
モックを使わず、実際の複数サービスを繋いだ状態で、サービス間の連携やデータの一貫性が保たれるかを検証します。
コンポーネントテストが「1サービスの内側」を見るのに対し、結合テストはサービス間やネットワーク越しの呼び出し、データの受け渡しを確認するのが目的です。
E2Eテスト
利用者と同じ条件で、システム全体を通して業務シナリオが目的を達成するかを検証します。
視点が「システム内部」ではなく「利用者」である点が、結合テストとの決定的な違いです。
最も本番に近い一方で、最も遅く・壊れやすいため、テストケースの本数は思い切って絞ることが多いです。
たとえばECサイトであれば、「商品を検索する」「商品をカートに入れる」「ログインする」「購入を完了する」といった一連の流れを、利用者と同じように操作して確認するイメージです。
内部のAPIが正しく連携しているかだけでなく、最終的に利用者が目的を達成できるかを見る点が、E2Eテストの大きな特徴です。
結合テストとE2Eは混同されやすい
実際のプロジェクトでは、「全サーバーを繋いで通すテスト」が結合テストとE2Eの両方を兼ねていることがあります。
技術的な連携確認(結合)と、利用者視点の業務確認(E2E)は本来狙いが異なります。
ただ、規模やコストの都合で一体運用されるのは現実的な判断と言えます。
大切なのは、「そのテストで何を確認したいのか」をチーム内で認識を合わせておくことだと感じました。
ここまでで、機能テストの全体像を確認できました。
次は、その先の非機能試験に入る前に、モニタリングの設計を整理していきます。
第2章 モニタリングを設計する
機能のテストが終わると、次は性能や障害に耐えられるかを見る非機能試験に進みます。
ただ、その前にひとつ用意しておきたいものがあります。それがモニタリング(監視)です。
監視はリリース後に整えるものというイメージがありますが、非機能試験の前に作っておくこともあります。
理由はシンプルで、非機能試験そのものが「監視が正しく動くかのリハーサル」になるからです。
試験環境にも監視を入れておけば、性能試験中に「閾値を超えたら正しくアラートが飛ぶか」まで一緒に確かめられます。
また、性能試験でレスポンスタイムやリクエスト成功率などを確認することもできます。
モニタリングに関して最低限おさえておきたいのは、SRE(Site Reliability Engineering)でよく使われる次の考え方です。
CUJ(Critical User Journey)
止まったら致命的なユーザー体験の一連の流れ。
監視設計では、まずCUJの選定から行います。
SLI(Service Level Indicator)
CUJが健全に動いているかを数値で表す指標です。
リクエスト成功率やp95/p99レイテンシなどがあります。
SLO(Service Level Objective)
SLIに対して定める目標値です。
「成功率99.9%以上」「p99レイテンシ2秒以内」などが該当します。
エラーバジェット
「100% − SLO」で表す、許容できる失敗の量です。
どこまで攻めた変更をしてよいかの判断基準になります。
これらをもとに「何をどの目標で監視し、異常時に誰へ通知するか」を先に決めておきます。
特に通知(アラート)まわりは、非機能試験内の障害検知試験で「本当にアラートが飛ぶか」を確かめることができます。
そのため、非機能試験に入る前に、監視と通知の設計を用意しておく必要があります。
ここまでで、機能の確認と、それを見守る監視の土台ができました。

まとめ
開発完了という言葉を聞くと、コードを書き終えて、画面やAPIがひと通り動く状態をイメージしがちです。
私自身も最初は、機能が動くことを確認できれば、リリースに近づいた状態だと思っていました。
しかし実際のプロジェクトを経験してみると、開発完了からリリースまでの間には、まだ確認すべきことがたくさんありました。
特に重要だと感じたのは、リリース前に確認する内容には大きく2つの観点があるということです。
1つは、作った機能が意図どおりに動くか。
もう1つは、リリース後に何か起きたとき、それに気づける状態になっているか。
この2つを分けて考えられるようになると、「今は何を確認している工程なのか」「このテストでは何を担保したいのか」が見えやすくなりました。
テストの種類や監視の考え方は、最初は用語が多くて混乱しやすいです。
ただ、それぞれの工程を「リリース後に安心して使える状態に近づけるための確認」と捉えると、全体の流れが理解しやすくなります。
後編では、性能・障害・運用の観点から、本番の利用に耐えられるかを確認する「非機能試験」について整理します。











前提:開発完了からリリースまでのフローは、プロジェクトによって大きく異なります。今回紹介するのは、テストの種類やモニタリングの設計などに関して、私が実際に経験した範囲になります。