
みなさん、こんにちは!
株式会社アイスリーデザイン・エンジニアリング部のYassanです。
入社1年目に参加したあるプロジェクトで、文字コードについて調べたことがありました。今日はその内容を紹介します。
背景
DBにデータを登録する時に文字化けによるエラーを防ぐため、文字コードについて詳しく調べる機会がありました。
JIS X 0208の規格に従ったDBがあり、JIS X 0208のJIS第一水準、JIS第二水準に対応していない文字は、DB登録時に文字化けが発生してしまいます。そのため、対象外の文字がDBに登録されないように事前に判定する処理を作りたいと思ったことがきっかけで調べてみました。
調べていく中で「符号化文字集合」と「文字符号化方式」という用語が出てきました。
符号化文字集合と文字符号化方式とは
符号化文字集合
単に「文字集合」とも呼ばれます。文字に一意に振られた番号のペア集合のことです。
イメージとしては、符号化文字集合は特定の文字を一定のルールに基づいてまとめた表的なものになります。
例として以下のような符号化文字集合(文字集合)が挙げられます。
・Unicode・・・符号化文字集合や文字符号化方式などを定めた、文字コードの業界標準規格。Unicodeの目的は、すべての書記体系の文字をひとつの統一された標準で表現することです。これにより、異なる言語や文化圏の文字が一貫して表示され、処理されるようになります。
・JIS X 0208・・・日本語の漢字、ひらがな、カタカナ、アルファベット、記号などを含む文字集合で、コンピュータや電子機器で日本語を扱うために広く使われています。
・GB2312・・・中国で使われる簡体字中国語を表現するための符号化文字集合です。
文字符号化方式
単に「符号化方式」「エンコーディング(encoding)」とも呼ばれます。
文字をコンピュータ内部で扱うためにバイナリデータ(ビット列)に変換する方法です。
コンピュータは基本的に数字しか理解できないため、文字を数字に対応付ける必要があります。文字符号化方式は、この対応付けを定義するものであり、文字の入力、保存、表示、送信などの際に使用されます。
例として以下のような文字符号化方式が挙げられます。
・Shift_JIS・・・日本語を含む文字列の符号化方式。シフトJISと表記されることもあります。
・UTF-8・・・Unicode で一番よく利用される符号化方式。
・EUC-JP・・・主に Linux 系システムで使用される符号化方式。
参考:とほほの文字コード入門
UnicodeとJIS X 0208の関係性
上記の符号化文字集合と文字符号化方式を理解した上で、UnicodeとJIS X 0208の関係性について調べました。
UnicodeとJIS X 0208の時系列は以下のようになっています。
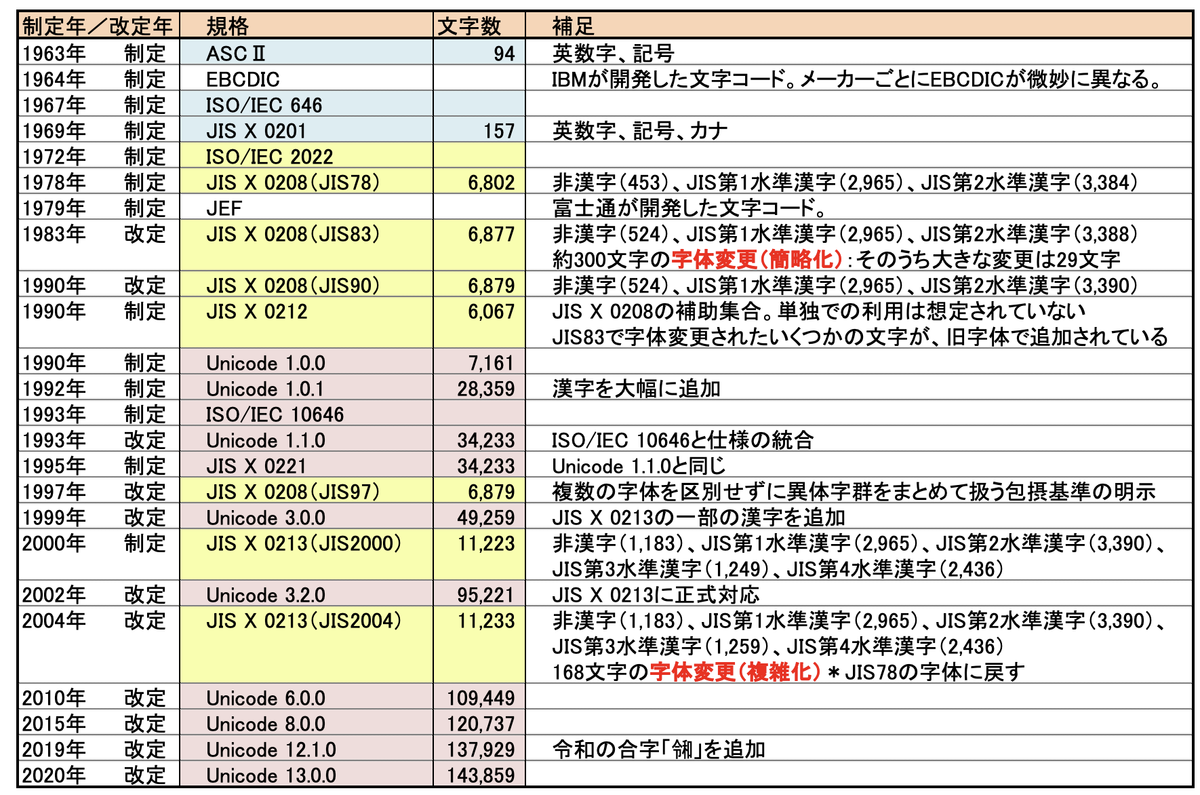
引用元:文字コードの歴史
表からわかることは、JIS X 0208の最終制定が1997年であり、Unicodeは直近も更新され続けているということ。文字が増えるにつれて色々な符号化文字集合と文字符号化方式が増えており、文字コードの歴史は、扱える文字の拡張の歴史でもあるということがわかります。
次に、包含関係で見ると以下のようになっています。

まとめると、JS X 0208規格に沿ったDBに対して、JIS X 0208に存在しない文字を登録すると、文字化けを起こすということになります。
例えば、1文字として認識されている「㋿」はUnicodeにはありますが、JIS X 0208には含まれていないため、DB登録時に文字化けしてしまいます。
JIS X 0208の水準について
最後にJIS X 0208の詳細についてもまとめます。
JIS X 0208は4つの水準があり、下記のようになっている。
・JIS第一水準・・・常用漢字とその他の人名用漢字が含まれています。
・JIS第二水準・・・比較的使用頻度が低い地名や人名などに使用される漢字が含まれます。
・JIS第三水準、JIS第四水準・・・業種によって必要になる特殊な記号などが含まれます。
ここまでの知識を踏まえて、改めてこのプロジェクトで開発したシステムのことや、システムで扱うデータの性質など理解が深まりました。
今後も、業務で経験したことや学んだことなどを発信していきたいと思います。
お読みいただき、ありがとうございました!








